23 Jul 2017
I recently started writing technical articles for Baeldung. My first article just got published:
Apache Commons Collections MapUtils
Currently I will not be getting the credit for the articles I write. So it appears under the name baeldung.
28 Mar 2017
Yesterday, I gave a full day training on Docker. It was a introductory level course covering basics of Docker and introducing tools like Docker Compose and Docker Swarm. I also demoed these features and conducted hands-on session.
I throughly enjoyed the process of preparation and delivering the training. I think I was able to communicate the material I had planned to deliver and was able to clear the doubts, concepts.
I made my slides as verbose as possible so that the students could follow the steps after the training also.
Experience with reveal.js
- This time I tried reveal.js based slides. I wanted something text based (preferably Markdown) format for preparing the presentation slides and reveal.js for perfect for it. I was able to prepare all my slides in single Markdown file.
- reveal.js is easy to pick once you have initial setup ready and not expecting something fancy in your presentation slide (see below). I think I spent around 4-5 hours during my preparation in learning, setting up and researching reveal.js. So if you are on tight schedule, it might be a big distraction (its also lots of fun to play around with) and better to stick with tool you are already comfortable with.
- reveal.js and Markdown were does not help you much with diagrams. I explored Typora, however it does not support drawing simple block diagrams (typical high level architectural diagrams) in it. And eventually you end up exporting the image file out of it and embedding it into your md file. I ended up creating/editing images myself.
- Animation of diagrams was another problem I faced. I ended up creating bulk images each showing part of the animation and sliding them one after the other. Need some better way to do this with reveal.js and Markdown.
Anyway, the final output of my slides was satisfying and I would prefer reveal.js instead of using any binary format like PowerPoint etc. In fact, in coming days I plan to convert all my old presentations into reveal.js.
Finally here is the link to my presentation. Press s key to see the presenter notes:
http://rockoder.com/introduction_to_docker
If you want to refer the Markdown code for these slides check out docker_slides.md on my github repo.
12 Feb 2017
So you are planning to containerize your product. You read the Docker docs, watched few videos and played around with basic Docker commands. But you are wondering, now what? How do you start containerizing this monolithic, legacy, enterprise product?
Here are few steps that could help you through the process and get you a starting point. This would be a three part article. This part covers the information you need to gather before starting to write the Dockerfile.
Understand the Product Installation
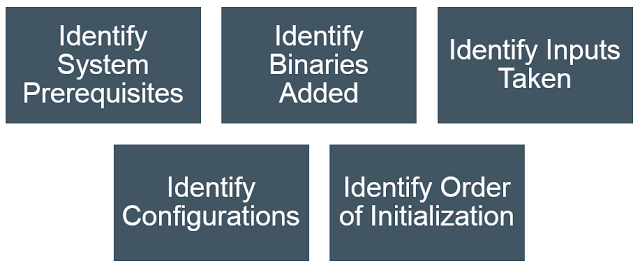
In this section, we’ll talk about the research you need to do and data that you need to collect which will be useful later while creating the Dockerfile and other scripts.
1. Identify System Prerequisites
Best place to start is look for the System Requirements section of the Product Documentation. Go find the documentation. Pray you have one.
Note the base OS on which the product is deployed. If you support multiple operating systems, start with the most popular Linux based OS on which the product is deployed. Docker on Windows is still at nascent stage and you don’t want to add one more unknown parameter in your research. Prefer Debian based OS like Ubuntu just for its ease of package management and installation.
Identify additional software and libraries which your product assumes to be present on the system before you being the product installation.
Also note the sizing guidelines for the server on which you deploy the product. Note the memory, CPU requirements. Preferably start with the smallest size supported.
2. Identify Binaries Added
What software are installed when you deploy or install the product? Are there third party software bundled with the setup. Transitive dependencies? Do you need JRE?
What inputs do you provide during the installation process? What are the default values during silent installation? What things are assumed and currently not configurable?
- DB details - Server details, DB credentials
- User credentials
- Installation location - location to put the binaries
- Product configurations - log level, heap sizes etc
4. Identify Configurations
Where are the product configuration files stored? What all things are configurable? What are the default values? What configurations are asked to the user during installation?
5. Identify Order of Initialization
Does your product spawns multiple processes or daemons running in background? What are they? In what order are those started? In what order do they stop?
Do not think about splitting the product right now. You would do it eventually, but not now. Right now the focus is on getting the product containerized.
16 Jul 2016
Many organizations, new and old, struggle to come up with a descent Software Design Document Template for the teams to follow. I plan to provide a template with various sections that could be considered while working on the software design. Not all sections may be applicable for each feature. Developer/Architect should pick up the relevant sections.
Contents
1. Introduction
Provide context for this architectural change or new feature.
Point to related User Stories in AGM, defects, wiki pages, research/approach wiki/docs, attachments (PPTs, Docs).
3. Definitions
Terminologies, Acronyms and their meaning, description etc.
4. Limitations of Current Product Functionality and Architecture
Limitations, Drawbacks, Defects, Issues etc. in existing product before implementing this feature/story.
5. Solution Highlight
Executive summary of architectural changes and/or new features. Along with section 4 (above), the reader should be able to understand the problem being solved, business context of the problem and how it is intended to be solved.
6. Acceptance Criteria
Identify the acceptance test criteria. This could include development test suite, smoke tests suite etc.
7. Functional Design
Use this section on highlight WHAT functionality is to be introduced/changed within the product. Provide details about the use cases, actors, scope etc. Below two sections combined should be able to capture clear understanding of the functionality from engineering point of view.
8. Architecture
High level architectural changes. Highlight what changes will be introduced as compared to existing architecture using old/new diagrams or colors/sections within the diagram. Following diagrams, as appropriate, can be used:
-
Context diagram
A very high-level diagram showing your system as a box in the center, surrounded by other boxes representing the users and all of the other products/systems that the software system interfaces with.
-
Container diagram
A high-level diagram showing the various web servers, application servers, standalone applications, databases, file systems, etc that make up your software system, along with the relationships/interactions between them.
-
Block/Component diagram
One per container, showing major components and their relationships.
9. Implementation Design
-
Domain Model Design
Relatively detailed design of the code/solution. Explain new classes introduced, classes which underwent major changes, design patterns used etc. Following diagrams, as appropriate, can be used:
-
Class Diagram
Explaining implementation of particular component. Also can be used to explain design patterns and future extensibility.
-
Collaboration Diagram
Showing high level communication between objects.
-
Sequence Diagram
Showing complex interactions between objects over time.
-
Data Model Design
Relatively detailed design of the new tables/columns. Explain purpose of each table/column, when/who/how of CRUD operations, normalization considerations etc. Also mention affected files (sql, xml, scripts). Following diagrams, as appropriate, can be used:
-
Entity Relationship Diagram
Showing relationship between the new tables/columns introduced.
-
CRUD Table
Chart showing CRUD operations performed by various processes on entities.
10. Development Considerations
-
Deployment
Describe hardware, system requirements and other deployment configurations like ports opened, firewalls etc.
-
Upgrade
Describe upgrade steps and files affected. Consider existing configuration files and data during upgrade. Also consider backup and rollback action plan.
-
Migration
Describe database migration plan. Explain tables affected, steps for migrations and scripts/tools involved. Also consider backup and rollback action plan.
-
Import/Export
-
Reports
-
Compatibility
-
Scalability and Performance
-
Security
-
Internationalization
11. External Dependencies, Blockers and Risks
12. Approvals
-
Dev Manager
-
QA Manager
-
Product Owner
-
Tech Pub Manager
-
Solution Architect
-
Product Architect
-
Support Manager
-
UX Manager
13 Oct 2014
Recently I gave hands-on Introduction to Boost in C++ Meetup held in Pune. The session went pretty well with 20-25 folks attending it on a Saturday morning.
I covered three Boost libraries:
- Lexical Cast
- Optional
- Any
I had intentionally selected header-only libraries so that the audience could start coding along with me without having to build the Boost.
Here are the slides that I had prepared:
I have also uploaded the code generated during the live coding session:
https://github.com/rockoder/boost-hands-on